Danh sách cạnh trong lý thuyết đồ thị là một cách tổ chức dữ liệu thường được dùng trong thuật toán tìm cây khung nhỏ nhất Kruskal, nó giúp bạn tiết kiệm chi phí lưu trữ và chi phí duyệt với đồ thị thưa.
1. Tổng quan về danh sách cạnh trong lý thuyết đồ thị
Danh sách cạnh trong lý thuyết đồ thị được lưu trữ vào mảng một chiều, mỗi phần tử của mảng sẽ thể hiện thông tin của 2 đỉnh kề nhau.
Với mô tả bên trên bạn có thể tạo cho riêng mình một struct dữ liệu của một cạnh gồm 2 thông tin, và khai báo một mảng thuộc dữ liệu đó. Tuy nhiên trong code tham khảo về nhập dữ liệu cho danh sách cạnh trong lý thuyết đồ thị dưới đây, mình sẽ tạo 2 mảng riêng mà không dùng struct.
a. Code biểu diễn đồ thị bằng danh sách cạnh c++
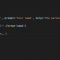
#define NMAX 100
int x[NMAX*NMAX+1], y[NMAX*NMAX+1];
int n, m, u, v;
cin >> n >> m;
for (int i=1; i<=m; i++)
{
cin >>x[i]>>y[i];
}
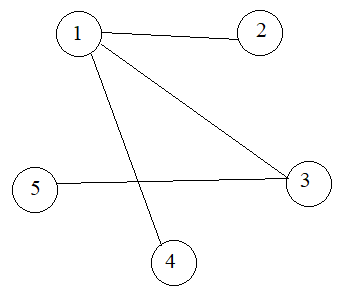
Hình ảnh minh họa ma trận đơn vô hướng không trọng số
b. Mô phỏng dữ liệu tổ chức danh sách cạnh theo ví dụ
X[i] y[i] i _________ 1| 1 2 2| 1 3 3| 1 4 4| 3 5
Các bạn có thể tham khảo thêm thuật toán tìm cây khung nhỏ nhất kruskal, được biểu diễn đồ thị bằng danh sách cạnh:
Cây khung nhỏ nhất QBMST spoj: Kruskal, Prim heap
2. Ưu điểm và nhược điểm khi dùng danh sách cạnh trong lý thuyết đồ thị
Dễ dàng biết được 2 đỉnh nào kề với nhau.
Cách tổ chức này khá dễ viết, chúng thường được dùng trong thuật toán căn bản như tìm cây khung kruskal.
Nếu chi phí duyệt và không gian lưu trữ của ma trận kề là N^2 thì phương án tổ chức dữ liệu bằng danh sách cạnh chỉ mất 2*m. Giảm được rất nhiều về chi phí và thời gian duyệt nếu đồ thị thưa (đồ thị có ít cạnh)
Nhưng khi ta muốn duyệt tất cả cạnh kề của một đỉnh nào đó, lúc này chẳng có cách nào ngoài việc duyệt hết danh sách cạnh đó và lọc ra để xử lí, đặc biệt là khi đồ thị dày (đồ thị có nhiều cạnh) thì thời gian duyệt sẽ tăng lên rất nhiều. Chính vì thế mà Kiểu tổ chức dữ liệu bằng danh sách kề được ra đời.